- 데이터셋
Netflix Movies and TV Shows
Listings of movies and tv shows on Netflix - Regularly Updated
www.kaggle.com
Kaggle에 올라와있는 Nexflix 데이터를 활용하였다. 2008년부터 2021년까지의 데이터를 확인할 수 있다.
- EDA
결측치, 데이터 형식 등을 파악하기 위한 EDA를 진행하고 전처리를 진행했다.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# csv 파일 읽어오기
url = "파일경로.csv"
netflix = pd.read_csv(url)
# 컬럼명 확인
netflix.columns
# 데이터 일부 확인
netflix.head(3)
결측치(NaN)가 있는 column들을 확인할 수 있다. 동시에 날짜 column인 date_added에서 날짜 형식이 어떻게 되어 있는지 확인가능하다.
# 결측치 및 데이터 형식 확인
netflix.info()
전체 행은 8807행으로 column별로 결측치와 데이터 타입을 확인할 수 있다. 위에서 살펴봤던 날짜 column인 date_added가 object 타입으로 되어 있어 to_datetime 전처리가 필요함을 확인했다.
# 결측치 비율 확인
# .isna( ) : 결측 값은 True 반환, 그 외에는 False 반환
for i in netflix.columns :
missingValueRate = netflix[i].isna().sum()/len(netflix) * 100
if missingValueRate > 0 :
print("{} null rate: {}%".format(i,round(missingValueRate, 2)))
결측치 처리가 필요한 column은 총 6개이다.
- 전처리
1. 결측치 처리
결측치 처리하는 데에도 여러가지 함수를 사용할 수 있다. 결측치 비율이 높은 경우 row 전체 삭제를 하게 되면 손실되는 데이터가 많아지기 때문에 fillna 또는 replace를 사용해서 결측치를 다른 값으로 대체해줬다.
# inplace = True : 원본 객체 직접 변경
# 결측치 비율 : country(9.44%)
netflix['country'].fillna('No Data', inplace = True)
# 결측치 비율 : director(29.91%), cast(9.37%)
netflix['director'].replace(np.nan, 'No Data', inplace = True)
netflix['cast'].replace(np.nan, 'No Data', inplace = True)
그 외에 결측치 비율이 1% 미만인 행들은 전체 행 제거로 처리하였다.
# 결측치 비율 : date_added(0.11%), rating(0.05%), duration(0.03%)
netflix.dropna(axis = 0, inplace=True)

그 결과 총 17개의 행이 제거되어 총 8790개의 행이 남고 결측치가 모두 채워졌다.

2. 데이터 타입 변경 & Feature Engineering
* Feature Engineering이란? 기존에 존재하는 변수를 활용하여 새로운 정보를 추가로 생성하는 과정
# 날짜 데이터인 date_added의 dt를 object에서 datetime으로 변경
netflix["date_added"] = pd.to_datetime(netflix["date_added"], format = 'mixed')
netflix["date_added"]간혹 하나의 컬럼 안에서도 날짜 형식이 여러개인 경우가 있는데 그럴 경우 format = 'mixed' 인수를 넣어주어야 쿼리가 원활하게 돌아간다.


날짜 형식으로 바뀌면서 년월일의 순서 및 형태가 바뀐 것을 확인할 수 있다.
# .dt.year : datetime에서 연도 정보 추출
# .dt.month : datetime에서 월 정보 추출
netflix['year_added'] = netflix['date_added'].dt.year
netflix['month_added'] = netflix['date_added'].dt.month
netflix.head(3)date_added 열에서 년도와 월만 추출하여 year_added와 month_added라는 새로운 열을 만들어줬다.
나중에 연도별, 월별 통계자료를 시각화할 때 유용하게 사용할 수 있다.
# rating 변수의 값 파악
netflix['rating'].unique()
넷플릭스 영상 등급의 경우 위와 같은 알파벳+숫자로 구분되어 있는데 각 등급이 무엇인지 확인이 어려우므로 의미를 알 수 있는 age_group 열을 새로 생성했다.
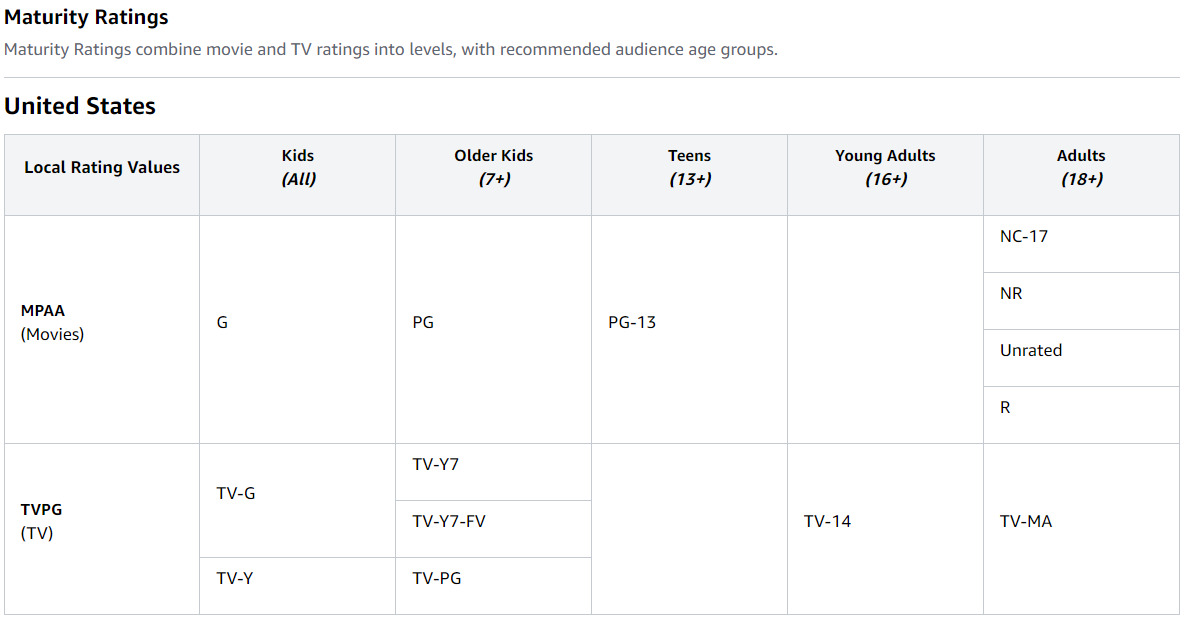
# 2. 시청 등급 설명표를 참고하여 Netflix의 rating 변수를 이용한 age_group 변수 생성
# netflix['age_group']를 생성하여 netflix['rating'] 값 삽입
# age_group 변수에 딕셔너리로 시청 등급에 대한 key, value 선언
# .map( ) : 사전에 정의한 내용을 변수에 적용
netflix['age_group'] = netflix['rating']
age_group = {'TV-MA': 'Adults',
'R': 'Adults',
'PG-13': 'Teens',
'TV-14': 'Young Adults',
'TV-PG': 'Older Kids',
'NR': 'Adults',
'TV-G': 'Kids',
'TV-Y': 'Kids',
'TV-Y7': 'Older Kids',
'PG': 'Older Kids',
'G': 'Kids',
'NC-17': 'Adults',
'TV-Y7-FV': 'Older Kids',
'UR': 'Adults'}
netflix['age_group'] = netflix['age_group'].map(age_group)
'Python' 카테고리의 다른 글
| [Netflix] WordCloud, 이미지로 결과 표현하기 (1) | 2024.05.31 |
|---|---|
| [Netflix] 시각화 (matplotlib.plotly, seaborn) (2) | 2024.05.31 |