3주간의 길다면 길고 짧다면 짧은 SQL 프로젝트가 끝이 났다.
체감으로는 참 길었는데 데이터를 보다 깊게 파고들기에는 짧게 느껴졌던 3주였는데, 정신없이 프로젝트 하고 나니 다 지나가버린 2월...🥲
SQL 프로젝트 데이터는 kaggle의 olist_dataset이었다.
발표가 3번이 있었는데,
1차에서 브라질 시장과 olist 비즈니스 모델 파악 및 데이터셋 EDA,
2차에서 1차 EDA한 것들을 깊게 건드려보면서 3차까지 가지고 갈 유의미한 주제들을 걸러내고 단 2-3가지 데이터들을 다각도로 더 깊게 분석하는 것이 권장되었다.

우리팀은 1차에서 브라질 지리적,경제적,문화적 특성과 이커머스 특징 및 olist 기업 분석을 진행했고, 시간분배를 잘 못해서 EDA는 거의 진행하지 못했다.
데이터셋이 어떻게 생겼는지 테이블, 컬럼명, 결측치 그리고 이상치만 확인한 정도..?
1차 발표 및 피드백
그리고 1차 발표를 한 결과, 우리의 피드백은 처참했다.
1. 비즈니스 모델이 불분명하고 겉만 핥는 느낌
→ Olist의 고객이 누구인지 파악이 안된 것 같다.
→ EDA가 제대로 되어 있지 않아서 배경지식만 말하는 붕 뜨는 느낌
2. 이해하기 어려운 시각화
→ 시각화는 설명을 안해도 설명이 될 만큼 이해하기 쉽게 하기 위해 사용하는 방법인데 이 시각화가 뭘 말하고 있는건지 전혀 모르겠다.
3. Pandas로 EDA해보면서 간단하게라도 훑었으면 좋았을 듯 하다.
→ 해당 데이터셋에서 결측치, 이상치가 중요한게 아니다.
→ 통계적으로 살펴봤어야 한다.
즉, 우리는 1차 피드백을 통해 우리가 가장 중점으로 생각할 것이 2가지임을 확인했다.
⇒ 비즈니스 모델 정확하게 파악
⇒ 제대로 된 EDA 필요
피드백을 통해 사실상 1차 발표 때까지 우리는 아직 아무것도 시작하지 않았음을 깨닫고,
2차 발표 전까지는 1. 비즈니스 모델을 제대로 파악하기, 2. EDA를 통해 데이터셋에 대해 완전하게 이해하기 그리고 3. 분석 방향성 정하기를 목표로 마케팅 전략인 4P를 적용해서 다각도의 EDA를 최대한 많이 진행하고자 했다.
*4P = Place, Product, Promotion, Price
2차 발표 준비
내가 한 것만 이만큼이고 다른 팀원들이 해온 것까지 하면 건드려볼 수 있는건 진짜 거의 다 건드려 본 것 같다.
(리뷰 텍스트 분석만큼은 하지 말자고 합의했던 부분이라 그 부분은 크게 건드리지 않았다.)
EDA를 통해 알게 된 점은,
1. 배송기간에서 분석할 것이 생각보다 없다.
: 주문접수 - 판매자 승인 - 택배사에 물품 전달 - 소비자에게 배송의 단계로 이루어진다.
: 판매자가 택배사에 물품을 보내는 기간은 2-5일 내외로 편차가 크지 않았고, 택배사로부터 소비자에 도착하는 기간의 편차가 크다.
→ 브라질의 넓은 국토면적이라는 지리적 특성이 반영된 것으로 Olist가 판매자에게 조언할 수 있는 부분이 아니다.
* 배송기간과 리뷰와의 상관관계는 보였지만, 위와 같은 이유로 Olist의 위치에서 마땅한 해결책을 제시하기 어렵다.
2. 시계열 분석이 어렵다.
: 2016년부터 2018년의 데이터라고 했지만 사실상 사용할만한 데이터를 거르고 보니 2016년은 11월 한달만 유의미했고, 2018년도 8월까지 밖에 없어서 온전히 있는 데이터는 2017년 뿐이었다.
→ 국가 이벤트에 따른 규칙적인 구매 특성을 파악하기에 데이터가 적절치 않다.
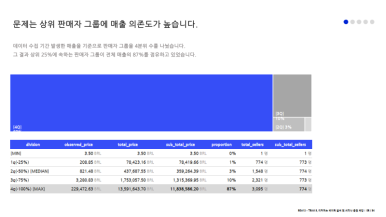
3. 매출의 대부분을 단 25%의 판매자가 만들어내고 있다.
: 판매자(seller_id) 별로 매출을 살펴보았더니, 3,095명 중 상위 25%(774명)의 판매자가 매출의 87%를 차지하고 있었다.
→ 판매자 매출에서 수수료를 떼서 수익을 얻는 것이 Olist의 비즈니스 모델인만큼 Olist의 실질 고객인 판매자들의 매출이 지극히 편중되어 있다는 점에서 지속 가능하고 더 큰 수익을 얻기 위해 고객(판매자)를 더 확보해야함이 분명해 보이고 분석의 의의가 있다고 판단했다.
이렇게 우리는 가리지 않고 EDA를 하고, 분석방향성도 정했으나, 2차 발표 이전까지 정한 분석 방향성에 대한 추가 분석까지는 시간이 부족했다.
2차 발표 및 피드백
그래서 1차 발표 때 했어야 할 Olist 비즈니스 모델 + 얕은 수준의 EDA 발표 + 인지한 문제 및 분석 계획을 2차 발표 내용으로 구성하였다.
1차 발표 피드백보다는 나았지만, 얕은 EDA로 인해 이 부분에 대해서는 여전히 좋은 피드백은 듣지 못했다.
다만, 앞으로의 분석 방향성에 대해서는 방향은 괜찮은 것 같아 분석만 잘 해보면 좋을 것 같다는 피드백이 있었다.
결론은 "지속 가능한 성장 방향을 제시하라."
1. 단순히 '판매자의 역량을 강화하겠다'는 목표는 너무 애매하다
→ 리뷰만족도를 높이겠다, 매출을 높이겠다 등 더 구체적인 목표 설정 필요
2. 주장이 많을 필요 없다. 3가지도 충분하다. 단, 깊이있는 데이터 필요
→ 이제는 너무 많은 EDA를 할 필요없이 선명한 인사이트를 도출할 차례.
3. 목표 설정은 좋은 것 같다.
⇒ 얕고 넓은 EDA 이제 그만
⇒ 설정한 목표대로 2-3개의 주장만 골라서 Deep Dive할 것
3차 발표 준비
1차보다는 2차 발표가 조금 더 나은 피드백을 받았지만, 2차 발표가 끝나고 새롭게 잡은 분석 방향성에 대해 다시 헤매기는 마찬가지였다.
게다가 문제를 도출했던 판매자별 매출을 확인했던 테이블과 컬럼을 잘못 잡은걸 발견해버렸다...
소비자가 실제로 결제한 금액인 payment_value를 기준으로 판매자의 매출을 집계했는데, 알고보니 해당 컬럼은 판매자별 매출을 확인하기에 적절치 않은 컬럼이었고 상품 금액인 price를 기준으로 잡아야지만 판매자 개별 매출을 집계할 수 있었던 것이다.
정말 다행히도 다시 price 컬럼으로 집계를 했을 때도 여전히 판매자 25%에게 지극히 편중되어 있는 현상이 유지되어서 분석 방향을 그대로 유지해 가지고 갈 수 있었다.
이것 외에도 분석하면서 자꾸 기준이 잘못 잡히고, 같은 내용을 각자 분석하고 합치는 과정에서 숫자가 일치하지 않아 꽤 고생을 했다.
더불어 상위 25%와 하위 75%의 두 판매자 집단의 비교분석이다보니 어떤 행동에서 두 그룹이 유의미하게 차이가 나는지를 확인해야 했는데 이 부분에서 서로 분석해오기로 한 부분이 두 그룹별로 비교가 되지 않고 두 변수의 상관관계까지만 분석이 된다거나, 앞서 했던 EDA에서 이 부분은 인사이트를 찾기 어려울 것 같다고 생각됐던 부분들도 다시금 분석하는 등 도통 진도가 나가지를 않았다.
그 과정에서 답답한 마음 + 3주라는 꽤나 긴 프로젝트 기간에 지쳐서 그냥 대충 포장해서 프로젝트 마무리할까 라는 마음도 있었던 것도 사실이었지만..!
강사님께서 '팀원, 개인 스케줄, 체력 등 어떤 이유도 분석을 제대로 하지 못한 적절한 핑계가 될 수 없다.'는 말이 떠오르면서 그렇다면 어떻게든 '내'가 기여할 수 있는 부분이 뭐가 있을지에 집중해서 최대한 긍정적인 결과를 끌어올려 보자 마음을 다시 다잡았던 것 같다.
나는 데이터셋에서 카테고리에서 인사이트를 뽑아낼만한 것이 분명히 있을 것 같다는 생각이 있었다. 그러나 73개나 되는 카테고리를 하나하나 다 뜯어보기에는 파이널 발표일까지 절대적인 시간이 부족했고, 어떤 관점에서 인사이트를 뽑을 것인지 그 목표를 분명히 하고 파고들지 않으면 시간만 버리게 될 것 같아 섣불리 걷드리지 못하고 있었다.
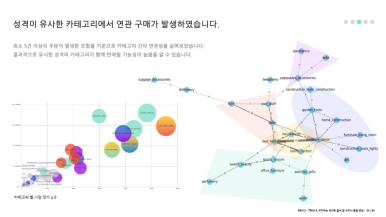
그 때 주문서에서 같이 구매된 제품들의 카테고리가 다르다면, 그 카테고리들 사이에 연관성이나 공통점이 있지 않을까?라는 생각이 들었다. 그리고 자주 같이 구매되는 카테고리가 실제로 존재한다면 이건 판매자에게 이런 조합으로 카테고리들을 취급하라는 판매팁으로 가이드를 제공할 수 있는 정보가 아닐까? 라는 생각으로 이어졌다.
그렇다면 73개의 카테고리를 개별적으로 분석하지 않아도 카테고리에서 충분히 유의미한 인사이트를 뽑을 수 있겠다! 싶어 실제로 어떤 카테고리 조합들로 구매가 많이 일어났는지 확인해보았다.
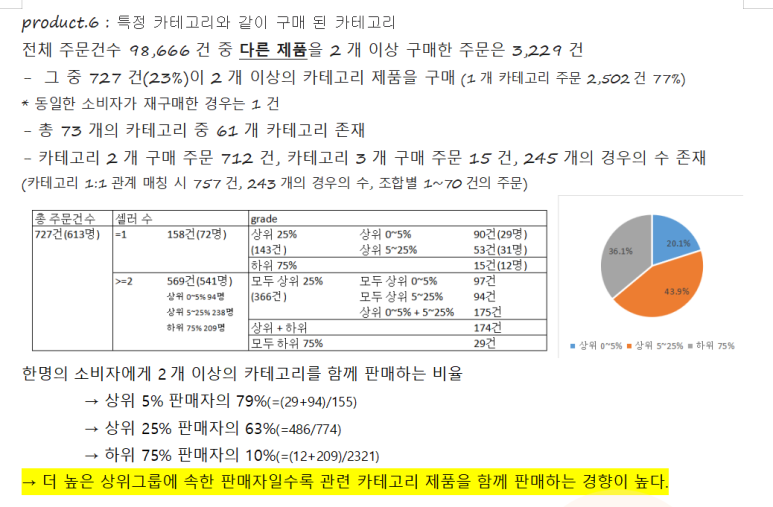
그 결과, 생활리빙, 전자제품, 패션뷰티 등 비슷한 성격들을 가진 카테고리들이 같이 구매가 이루어 진다는 것을 발견했다. 그리고 이러한 구매들의 판매자를 상위 25%와 상위 75%로 나누어 살펴본 결과 약 8-90%의 연관판매가 모두 상위 25% 판매자들에게서 발생한다는 것도 발견할 수 있었다.
이를 한번 더 상위 5%와 5~25%로 쪼개봄으로서 상위 판매자일 수록 이러한 연관판매 경향이 높다는 것도 확인했다.

연관카테고리 분석 이후 추가 분석하였다.
팀원들과 이 내용을 공유하여 더 디벨롭 시키고 어떻게 발표에 녹이면 좋을지, 어떤 방식으로 판매자에게 가이드로써 제안할 수 있을지 고민 끝에 상위 25%와 하위 75% 판매자 그룹을 단일카테고리 판매자와 다중카테고리 판매자로 한번 더 그룹핑하여 가이드를 제시하기로 결론이 났다.
파이널 발표 및 피드백
그래서 파이널 발표는 아래와 같은 흐름으로 ppt를 구상하였다.

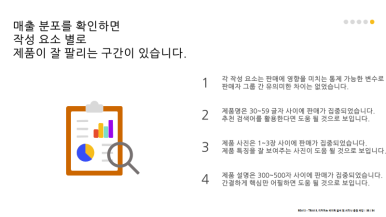
상위 25%의 판매자에게 매출이 편중되어 있고, 이는 중개수수료를 챙기는 Olist의 비즈니스 모델 특성상 사업지속성에 있어 해결이 필요한 문제임을 제기하고,
상위 25%의 차별된 특성을 분석하여 하위 75%의 매출을 증진시키기 위한 가이드를 제시하겠다.
판매자를 상위 25%와 하위 75%로 나누어 두 그룹을 비교분석한 결과, 상위 25%와 하위 75%의 행동에서 가장 큰 차이점은 2가지였다.
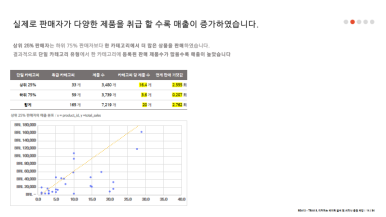
- 상위 25%의 판매자 1명 당 취급 제품 수가 더 많다.
- 제품 간의 연관판매 전략을 더 잘 이용하고 있다.
이에 우리는 하위 75% 판매자들이 취급해야할 최소한의 제품수를 상위 25%에 의거하여 제시하고, 2개 이상의 카테고리를 취급하려는 경우 연관된 카테고리를 확인하고 이에 따라 확장할 것을 제시하는 가이드를 만들었다.
이와 더불어 두 그룹이 상품페이지를 구성하는데 있어 사진개수, 제목길이, 설명길이에서 어떤 차이가 있을지를 같이 알아보면서 소비자들의 클릭을 유도하는 최적의 상품페이지 작성 가이드를 함께 제시하였다.
마지막으로 이 모든 흐름을 핵심만 정리 및 요약하며 마무리했다.
파이널 발표 결과는 우리 팀원들이 생각했던 것보다 훨씬 좋았다. 아니, 사실 대성공이었다.
1. 연관 카테고리 분석 부분에서 다각도의 분석을 보여주어 신입을 넘어서 경력의 레벨까지도 보여줬다.
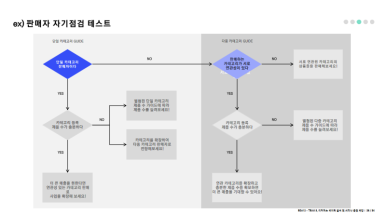
2. 분석한 내용을 어떻게 가이드할지 자기점검 테스트 예시까지 만들어서 보여준 것도 아주 "판타스틱"했다. 🥹
3. 상품페이지 분석 부분에서는 깊은 분석을 통한 인사이트 추출이 조금 아쉽다.
4. 단, 시각화에 있어서 내용은 많은데 결론이 자료에서 선명하게 드러나지 않고 청중에게 해석을 직접 하게 만드는 것이 아쉬웠다. (→ 직접 해석하게 만들면 발표내용의 집중도가 떨어진다.)
5. 마지막에 Wrap-Up으로 문제정리~분석결과~기대효과까지 한눈에 볼 수 있게 정리 요약한 것 좋았다.
사실 이렇게까지 호평을 들을거라 전혀 예상하지 못했는데, 시각화로 전달하는데 있어 더 친절하게 결론을 전달하지 못한 부분에 대한 아쉬운 평은 있었지만, 납득 가능한 문제제기, 분석 논리 전개와 더불어 가이드 예시를 만든 것에 대해 극찬을 들어서 어안이 벙벙하면서도 기분이 너무 좋았다. 3주 간의 고생이 다 인정받은 느낌이었달까!
그리고 몇일 뒤 받은 프로젝트 점수는 무려 🎊100점 만점🎉

프로젝트 종료 후 느낀 점
지난 파이썬 프로젝트도 그랬지만, 이번 SQL 프로젝트를 진행하면서도 절실히 느꼈던 점은 데이터 분석가에게 있어 파이썬, SQL 같은 프로그램 활용능력은 분석을 위한 부가적인 (그렇지만 꼭 필요한) 역량일 뿐 실제로 분석을 잘하기 위해서는 데이터를 여러 관점에서 바라볼 줄 알고 그것이 무슨 의미를 가지는지 해석할할 줄 아는 능력과 그 결과를 다른 사람들에게 온전히 잘 전달할 수 있는 커뮤니케이션이라는 것이다.
팀 프로젝트이다 보니 진행 과정에서 보다 중요하다고 생각하는 우선순위가 조금씩 달라서 (가령 스토리텔링, 시각화, 분석깊이...) 소통이 잘 되고 있는건지 의문이 들 때가 간혹 있었다. 내 경우에는 데이터셋 파악과 깊은 분석 내용이라는 알맹이 자체가 있어야 스토리 텔링과 시각화 같은 그 다음의 것들을 할 수 있다는 입장이었다. 그리고 다른 분들의 경우 열심히 분석해도 이를 잘 전달할 수 있도록 다듬고 ppt에 충분히 녹여낼 시간이 필요하다는 입장도 있었다.
그러다보니 나는 마지막까지도 분석에 깊이를 더해보고자 노력했고, 또 다른 팀원의 경우 ppt를 위한 개략적인 슬라이드 구성을 진행하는 등 각자 조금 더 중요하다고 생각하는 부분들을 개인적으로도 보충해가면서 마무리를 했는데, 지금 끝나고 나서 되돌아보니 팀원 모두가 분석 깊이에만 치중했다면 결국 발표에 분석결과를 온전히 녹여내지 못해 설득력이 떨어지는 발표가 되었을 것이고, 스토리텔링에만 집중했다면 논리성이 떨어지는 분석이 되었을 것이라는 생각이 들었다.
오히려 분석 프로젝트의 우선순위가 조금씩 달랐던 것이 특정 부분에서 크게 부족함 없이 전체적인 프로젝트의 퀄리티를 높일 수 있었던 우리팀의 큰 장점으로 작용했던 것 같다. 그리고 각자의 파트에서 남들보다 더 많이 기여하고 서로가 서로에게 살을 붙여 나가면서 보완할 수 있었다는 생각이 들었다.
또 그 과정에서 다른 사람들을 보면서 내가 잘하는 것과 보완해야 할 점들이 명확하게 보여서 내 역량을 스스로 점검해볼 수 있는 좋은 기회이기도 했던 것 같다.
(나는 데이터셋을 파악하고 유의미한 관계를 찾아내는 것을 잘하는 반면, 그것을 이해하기 쉽게 전달하는 부분에 있어서는 부족함이 많다고 느껴 커뮤니케이션 능력 개발에 있어 보다 더 정진해야겠다고 느꼈다.)
아무튼 이렇게 프로젝트를 진행하면서 분석가가 어떤 일을 하는지 몸소 이해할 수 있었고, 다음 프로젝트도 신입 같지 않은 경력같은 분석을 보여주고 싶다는 욕심이 생긴다. 시간이 가는대로 나를 흘려보내지 않고 부트캠프 기간동안 최대한 많은 것을 배우고 분석가 마인드를 탑재한 진정한 데이터 분석가가 되도록 노력해야겠다. 💪
'분석 프로젝트' 카테고리의 다른 글
| [Yammer] A/B Test 유의성 검정 (1) | 2024.05.30 |
|---|---|
| [Yammer] 검색 기능(Search Functionality) 분석 (1) | 2024.05.28 |
| [Yammer] WAU(Weekly Active Users) 하락 원인 분석 | 신규유저, 기존유저 Cohort WAU, Device별 WAU (0) | 2024.05.27 |