코호트 분석이란?
특정 기간 동안 공통된 특성이나 경험을 갖는 사용자 집단. 그룹 단위로 분석하는 방법을 말한다.

예시) 수도권에 사는 20대 후반 여자가 구글 서치 중에 배너 클릭으로 서비스에 진입했다.
1. 수도권 cohort - 지역
2. 20대 cohort - 연령
3. 여자 cohort - 성별
4. 구글 검색 cohort - 유입경로
5. 배너 클릭 cohort - 유입경로
그러면 사용자 집단을 그룹핑할 수 있는 방법은 다양하다. 예를 들어도 5개의 기준으로 코호트 분석을 해볼 수 있다.
보통은 Weekly, Monthly로 보는 경우가 많다.
Cohort 분석 목적
사실 대부분의 고객분석방법론의 목적은 서비스를 개선점을 찾아 개선, 고객의 만족도 향상을 통해 궁극적으로 매출 향상에 기여할 수 있도록 하는 것이다. Cohort 분석도 마찬가지로 고객 행동 패턴을 이해하고 인사이트를 발견해서 유저 경험 개선 및 매출 극대화를 위한 방법이라고 할 수 있겠다.
지금까지 있던 회사 내의 이벤트를 트래킹하고 개선이 필요한 이벤트, 효과가 좋았던 이벤트를 확인하는데 유용한 방법이다.
Cohort 분석해보기
일단 코호트 분석할 파일을 가져와 전처리를 진행해줬다.
1. 전처리
# 필요한 라이브러리 불러오기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import scipy.stats as stats
from datetime import datetime
# 파일 불러오기
url = '파일경로.xslx'
df = pd.read_excel(url)
# 데이터타입 변경
df['order_date'] = df['order_date'].astype(str)
df['charges'] = df['charges'].astype(int)
# strptime : string 데이터를 time 데이터로 변경(형식 지정)
# strftime : 시간 데이터의 format을 변경
df['order_ym'] = df['order_date'].map(lambda x : datetime.strptime(x, '%Y-%m-%d').strftime('%Y-%m'))
# user_id별 최초주문일자 가져오기
tmp_order_ym = pd.DataFrame(df.groupby('user_id').order_ym.min()).reset_index()
# column명 변경
tmp_order_ym.columns = ['user_id', 'first_order_ym']
tmp_order_ym.head()
# on = join할 값, how = join 방식
df = pd.merge(df, tmp_order_ym, on=['user_id'], how='left')
df.head()

# order_ym과 first_order_ym의 month 기간 차이 구하기
from datetime import datetime
from dateutil.relativedelta import relativedelta
# 두 날짜의 차이를 월 단위로 계산하는 함수 정의
def month_diff(date1, date2):
rd = relativedelta(date1, date2)
return rd.years * 12 + rd.months
# 문자열을 datetime 객체로 변환하고 월 차이 계산
df['month_diff'] = df.apply(lambda row: month_diff(datetime.strptime(row['order_ym'], '%Y-%m'), datetime.strptime(row['first_order_ym'], '%Y-%m')), axis=1)
2. 여러 기준별로 코호트 분석
- 월매출 기준
# 금액기준 cohort
# 소수점 제거 (소수점 제거하려면 null값이 없어야 함)
cohort_month = pd.pivot_table(df, columns='month_diff', index='first_order_ym', values='charges', aggfunc='sum').fillna(0).astype(int)
cohort_month
# 히트맵 그리기
plt.figure(figsize=(22, 6))
ax = sns.heatmap(cohort_month, annot=True, fmt='d', linewidths = 1, cmap='cividis')
plt.title('cohort by month profit')
plt.show()
첫구매한 달인 첫번째 열을 수직으로 봤을 때, 2010-01, 2009-11, 2010-02에 월매출이 가장 높은 것을 알 수 있다.
이는 1월에 회사에서 어떤 이벤트를 했는지 살펴보고 그 이벤트에 비용을 더 투자를 하거나 반대로 수익이 낮은 달에 진행한 이벤트의 비용을 줄이는 전략을 세울 수 있다.
- 월사용자 기준
# user_id 수 기준 cohort
cohort_month_user = pd.pivot_table(df, columns='month_diff', index='first_order_ym', values='user_id', aggfunc=lambda x: len(x.unique())).fillna(0).astype(int)
cohort_month_user
# 히트맵 시각화
plt.figure(figsize=(22, 6))
ax = sns.heatmap(cohort_month_user, annot=True, fmt='d', linewidths = 1, cmap='cividis')
plt.title('cohort by user')
plt.show()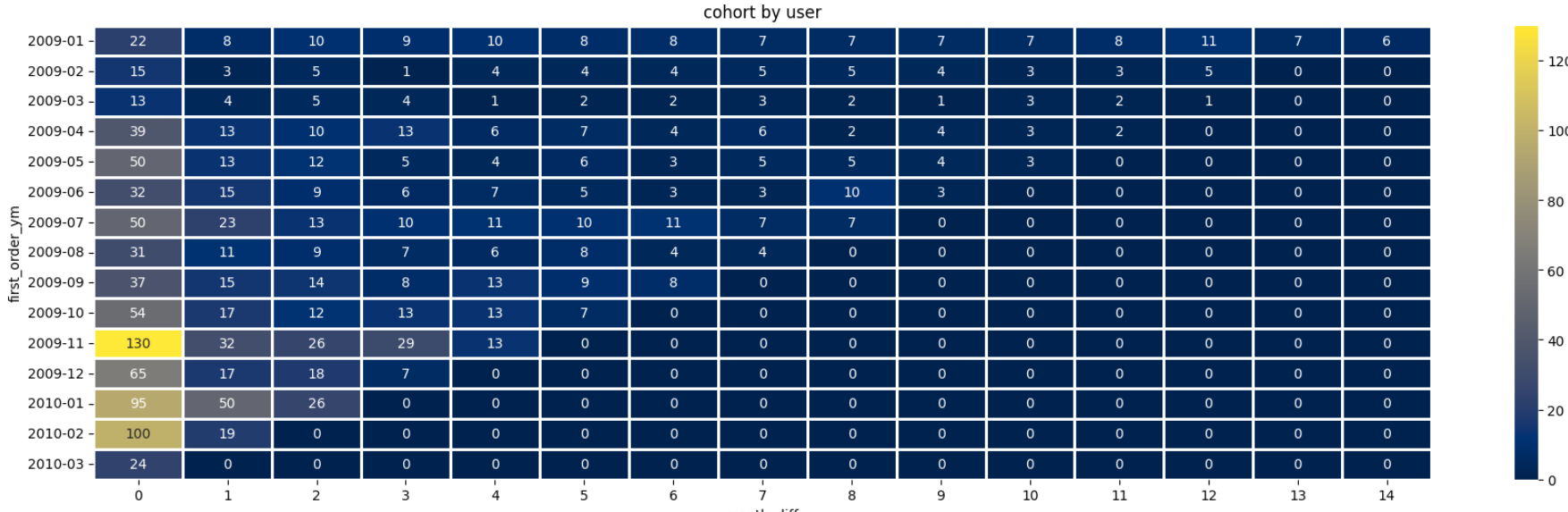
이번에는 기준을 월별 사용자 기준으로 코호트를 살펴보았다.
월매출과 마찬가지로 Top3는 2010-01, 2009-11, 2010-02 이지만 2009-11은 사용자 대비 매출로 보았을 때 오히려 효과가 그리 좋지는 않았다고 판단할 수도 있다.
- 객단가 기준
# 객단가 기준 cohort
asp_df = round(cohort_month/cohort_month_user).fillna(0).astype(int)
asp_df
# 히트맵 시각화
plt.figure(figsize=(22, 6))
ax = sns.heatmap(asp_df, annot=True, fmt='d', linewidths = 1, cmap='cividis')
plt.title('cohort by month_profit per user')
plt.show()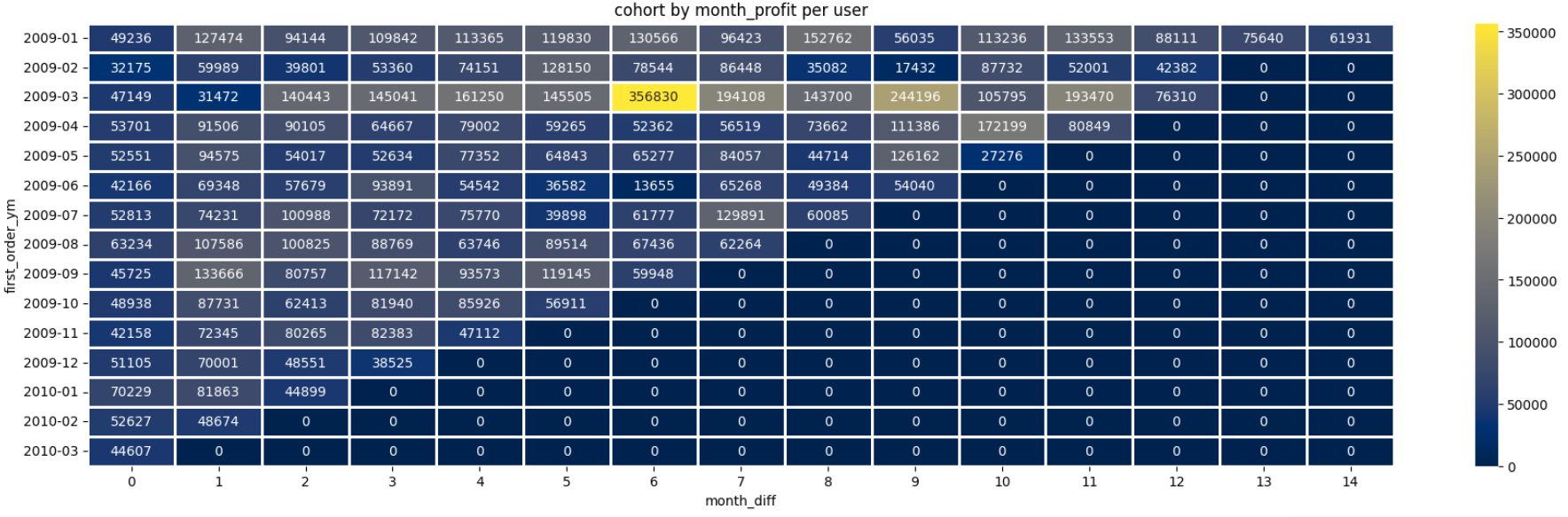
객단가를 기준으로 다시 살펴보면 2010-01은 여전히 가장 높은 객단가를 보여 이 기간동안 진행했던 어떤 이벤트나 상품이 효과가 좋았는지 찾아보면 좋을 것 같다.
그 밖에도 2009-03에 첫구매를 한 고객들은 객단가가 압도적으로 높고, 2009-02의 첫구매 고객들을 다른 달보다 이탈이 더 빠르다 등등 코호트 데이터를 통해 현상을 읽어낼 수 있겠다.
이렇게 유의미해 보이는 부분을 찾았으면 Deep dive 하면서 성별, 나이 같은 세부 기준으로 한번 더 쪼개어 살펴보는 것도 의미가 있다.
'분석방법론' 카테고리의 다른 글
| A/B Test (0) | 2024.05.30 |
|---|---|
| 퍼널분석(Funnel Analysis)과 (A)AARRR은 어떻게 다른가? (0) | 2024.05.30 |